A technical breakdown of the Dropback Data Engine, the new frontier of extensible backend infrastructure for elite college sports programs.
Everyone's looking for an edge.
College GM's know that innovating in-house — on new systems, processes, models, analytics, and strategies — is the way the pros get it.
But two things are simultaneously true:
- Teams are drowning in useful data.
- Teams are starving for answers.
That sounds like a contradiction, but it's the whole problem that Front Offices are facing in one sentence.
Why is this still so hard?
The Problem (The mistake Front Offices make)
When your data is scattered, the instinct is to gather it: Pull PFF and Hudl and track times and scouts' notes and your recruiting CRM into centralized repositories.
The problem is: Putting two spreadsheets in the same folder does not make them agree.
The hard part of sports data was never where it lives. The hard part is that the data doesn't agree about who, about what, about when, or about whose truth wins. No amount of storage centralization fixes that.
You can centralize a decade of contradictory data into a beautiful-looking web application and end up with exactly the same mess you started with, only larger.
You can throw more people at these problems; manually scrape and structure and match and merge and extract insights from raw data every time you want new information.
But this doesn't scale.
Getting answers or building new analytical models takes days or weeks because all of this crafty data wrangling is required for every single new question.
The Solution: The Dropback Data Engine
For two decades, every sports software company has sold the same thing: a black-box dashboard with their data and their queries, sitting between you and the answer. You get the chart they wanted you to see.
Our solution is not that. It is the substrate — the brain — and you build on top of it.
No sports organization has solved this problem because they don't have the time or resources to do what we've done: Spend 24 months heads-down building infrastructure.
Teams are too busy trying to provide real day-to-day value to their staffs, of course.
That's where Dropback comes in. We've built a low latency "engine" for sports data that anyone can build on top of.
- Capable of trillion-row scale
- Able to answer any question imaginable, in milliseconds
- Ready for the AI era
These are the four breakthrough innovations of the Data Engine:
Innovation #1: Universal Entity Record Consolidation
Here's the problem nobody appreciates until they try to build this in-house:
Marcus in PFF, Marcus in Hudl, Marcus in your scouts' notes, and Marcus in your Recruiting Database are four different records with four different IDs, four spellings, and no shared key.
They're the same kid. But no feed will ever tell you that. The fact that they're the same human being is not in the data. It has to be figured out.
Computer scientists call this probabilistic record linkage or entity resolution — a problem the data community has been formalizing since the Fellegi–Sunter model in 1969. The theory isn't the hard part anymore; the hard part is doing it well, at scale, on a moving target where the right answer keeps changing. Most sports systems skip the problem entirely by trusting whichever ID a feed hands them. We treat every identity as a hypothesis, score the evidence, and let the conclusion sharpen as more shows up.
It's hard because:
- the evidence is partial and contradictory
- new sources show up constantly
- the right answer can change as you learn more
A naive system treats identity as a given — it trusts whatever ID a provider hands it — and then quietly produces wrong answers forever because half the records secretly describe the same person.
The Engine continuously resolves which records across every source refer to the same real-world thing, and binds them to a single canonical identity. That binding isn't written in stone either: it's a living conclusion that gets sharper as more evidence arrives and as our matching logic improves.

The payoff is that everything downstream gets to assume what no feed will ever guarantee on its own:
one player, one identity, one thread to pull.
The clear majority resolve automatically. The truly ambiguous ones get surfaced for your team to decide — instead of being guessed at, buried, and left to contaminate every report you'll ever run. A program can trust an answer that is willing to say where it was unsure.
Identity outlives the role
There's a deeper layer to this — and in an era defined by the portal and the coaching carousel, it might be the most important idea in the system:
A player is not the same kind of thing as the human being underneath.
A player is a role, and roles are temporary. The human is permanent.
The same person is a recruit, then your player, then a name in the portal, then somebody else's player, then a grad assistant, then a position coach on a staff you gameplan against.
Every system you've ever used stores that as five unrelated records — because to each feed, it was a different row in a different season in a different context. The continuous human being connecting all of it simply does not exist anywhere in their data.
In the Data Engine, it does.
In data-warehouse terms this is the slowly changing dimension problem — and almost every production system handles it badly, collapsing a person's history into whichever role was most recently observed. The Engine maintains a permanent identifier for every human and every institution, and binds each role to it with its own validity window. It's the same pattern that lets medical records survive an insurer change or historical archives track an institution through a merger — applied to a domain where the underlying entities move faster than almost any other.
The role tells you what someone was doing in a given window. The identity beneath it tells you it was the same someone the whole way through.
The consequence is a question nobody else can even pose:
Follow a human across every school and role they've ever touched — and ask what you knew about them at each step.
The portal stops being a black box. It becomes a thread you can actually trace.
Innovation #2: Append-Only Immutable Storage
Never. Overwrite. Anything.
Most databases are built to hold the present. When a fact changes, the old value gets updated in place and the previous one disappears.
That's fine for your bank balance. It's catastrophic for a sports program, because your entire job is judgment over time. You cannot study your own judgment if the record keeps quietly erasing it.
So our commitment is almost stubborn in its simplicity:
We never overwrite what a source said.

This pattern has a name, append-only storage, and it's the same architectural choice that lets financial ledgers reconstruct any account state at any historical moment, lets Git replay a repository at any commit, and lets blockchains verify a balance from the genesis block. The trade-off is more storage and more compute. The payoff is a system whose memory is permanent and whose past is queryable — the only foundation strong enough to support the next two innovations.
Every observation lands in a raw bronze tier exactly as the source sent it, stamped with what it said and when it arrived. From there, the Engine derives a silver layer — also append-only — where canonical truth is built up over time. Nothing is destroyed. Nothing is "edited in place."
It's the foundation of truth, because it makes the raw history permanent and auditable. When you ask later:
"How did our Midwest regional scout have Marcus graded during his junior year, but before his position switch?"
…the answer exists, untouched, because no later update was allowed to step on it.
A system that overwrites cannot answer that question at any price. A system that remembers can answer it for free.
Innovation #3: Derived, Bitemporal Truth
Once observations are permanent and identities are resolved, you face the real question.
Marcus's height is listed three different ways across three feeds, and your scout has a fourth. What is his height? His position isn't one value either — it's a freshman value and a junior value, a special teams value and a defensive value, a "what he played" and a "what we think he is."
Real facts move along several axes at once, and through time.
The lazy answer is to pick one and store it. The moment you do that, you've thrown away the disagreement (often the most useful part of the data) and you've created a number that nobody can reproduce or argue with. Worse: when a better source arrives next week, your stored answer is stale, and you have no principled way to update it.
Database researchers call this a bitemporal model with qualified facts. Every observation carries when we learned it on append-only storage; every fact that needs to travel through time carries the dimension it varies along — season, week, package, scout. It's the model adopted by the SQL:2011 temporal standard, the same idea Wikidata uses for qualifiers, and the same conceptual move that powers modern stream-processing systems where the canonical answer is always derived from a permanent record — never stored as a single opinion.
It's almost unheard of in sports software, where most vendors still treat yesterday's reality as a deleted row. For the first time, you don't have to just take whatever a vendor gives you.
So in the Data Engine, canonical truth — the value the platform presents as "the real one" — is never a stored opinion. It is derived. Truth is computed from the full body of observations and the resolved identity, by rules you can inspect and improve. Truth is a function, not a fact someone typed in once.
That one design choice is why the Engine can heal:
- when matching gets smarter, truth recomputes
- when a rule changes, truth recomputes
- when a new source arrives, truth recomputes
All the way back through history, automatically. You never re-run anything by hand.
And because time isn't a timestamp bolted onto a row — it's built into the shape of truth itself — every question is asked "as of" some moment:
- What was his grade then?
- Who was on the roster that week?
- What conference were they in that season?
Boise State was Mountain West in 2023 and Pac-12 in 2026. A player was a safety as a freshman and a nickel by junior year. Both are true — each in its own window. A program that can't hold both at once can't reason about its own past.
Time travel isn't a trick we added. It's what you get once you refuse to overwrite and you treat truth as derived.
Innovation #4: Graph-Native, Schema-Flexible Storage
For the easy stuff, you don't need anything clever.
A "wide" table works fine: one row per player, one row per game, a column for each stat.
If that were all sports data was, you wouldn't need Dropback. And anyone pitching you a fancy dashboard or app for storing players and games is selling you complexity you don't need.
The value is in the questions a wide table can't answer no matter how wide you make it.
Relationships are not columns
The interesting questions are rarely about one row. They're about how rows relate:
"Every high school that has sent a player to a current conference rival who later entered the portal."
That's a question about chains of relationships across time — and a relationship is not a column.
This is the difference between the relational model (rows and columns, designed in 1970 to optimize storage) and a graph model (vertices and edges, designed to optimize traversal). The relational model is a beautiful tool for the questions it was designed for. It's a notoriously bad tool for chains of relationships, which is the shape of every interesting sports question. The Engine treats every relationship as a first-class edge with its own validity window, so traversing them is a query — not a migration.
You can bolt on join tables, but now every relationship (team, high school, agent, conference, staff, roster membership) is bespoke structure you design and maintain by hand — and none of it knows anything about time.
Open-ended attributes
Your scouts' tags. Your proprietary metric. The thing you decided to track last Tuesday.
In a wide table, every new idea is a schema change. You end up thousands of columns wide and mostly empty, with a migration standing between your analyst and every new thought.
Schema-rigid databases force every new idea into a structural change: a migration, a release window, a meeting. Schema-flexible systems — knowledge graphs, semi-structured stores, the academic entity-attribute-value model — trade structure for runtime extensibility. The Engine takes a stricter cut: a typed catalog of entities and attributes, where adding a new metric or tag is a configuration change, not a migration.
You get the ergonomics of a notebook on top of the performance of a warehouse.
Your truth, on top of ours
Belief inside a program is perspectival, and the Engine respects that.
The Engine derives its best canonical answer from every source it can see. Your staff often knows better.
So your truth — your scout's position call, your corrected height, your grade — layers on top of the Engine's answer, while still inheriting the platform's best guess everywhere you haven't weighed in.
This is a layered belief model — the same pattern that shows up in collaborative filtering, in version-control merges, and in how Wikipedia reconciles edits with sourced claims. Your edits aren't sticky notes layered on top of someone else's truth. They flow through the same machinery as every other observation — attributed to you — which is why a correction you make stays put when the next vendor feed contradicts it, and why it shows up consistently across every surface.
One truth, every surface
There's a quiet lie in most stacks: the live screen and the deep report are built off different copies of the data. They drift. Once they drift, nobody trusts either one.
We use Zero and some specially-crafted OLAP ingestion pipelines to make instant reactivity a guarantee.

Most stacks read the live screen and the analytical report from two physically different databases — an OLTP store for the app, an OLAP warehouse for the analyst, with a fragile nightly ETL pipeline between them. The Engine reads both surfaces from a single source of truth: realtime queries hit one materialization, analytical queries hit another, but they're derived from the same place. There is no nightly job because there is no second copy.
Reassign a player and the roster screen moves instantly — and the next analytical run already agrees.
There is no "which export is current," because there is one truth wearing two faces.
What we're actually announcing
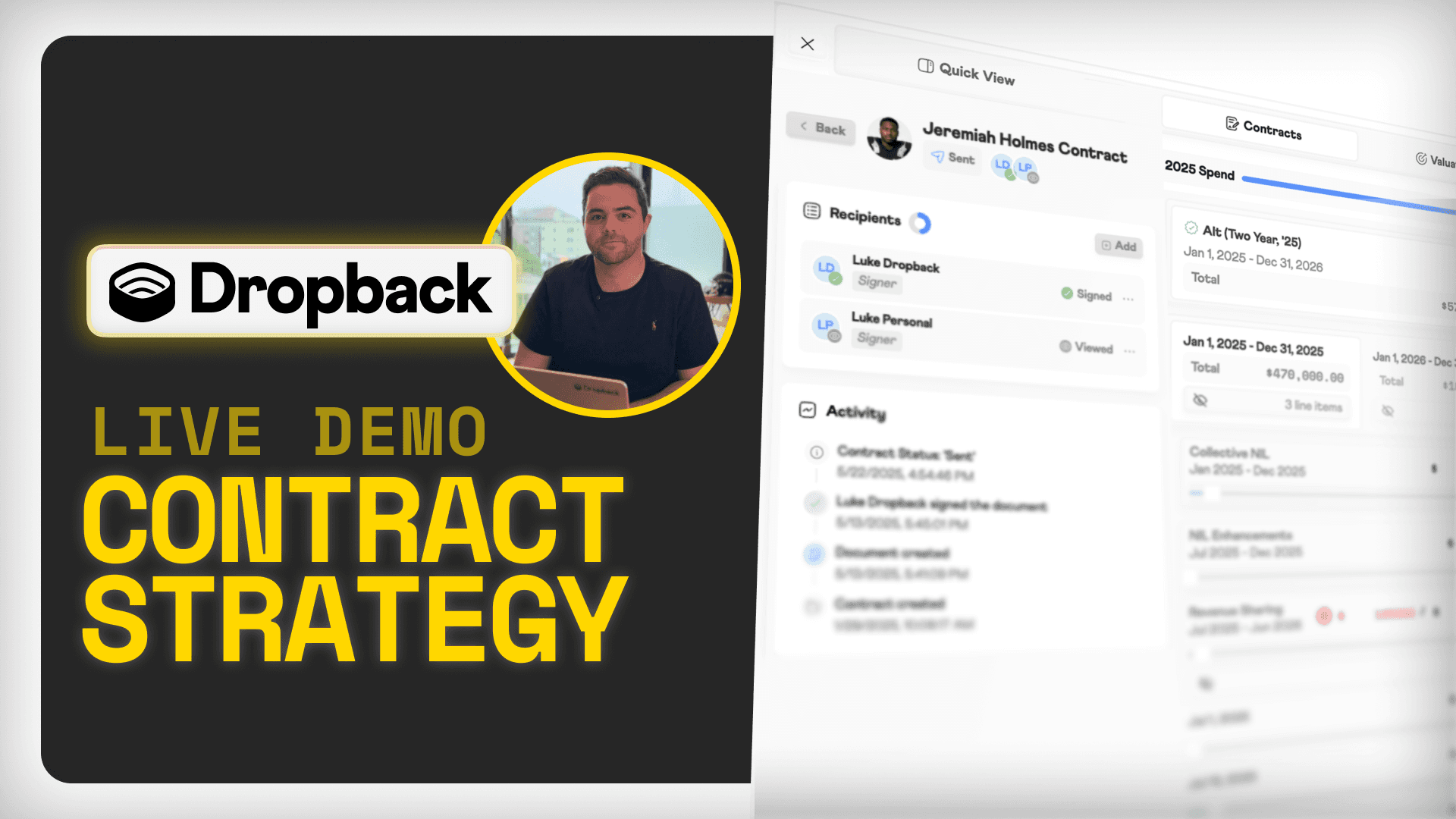
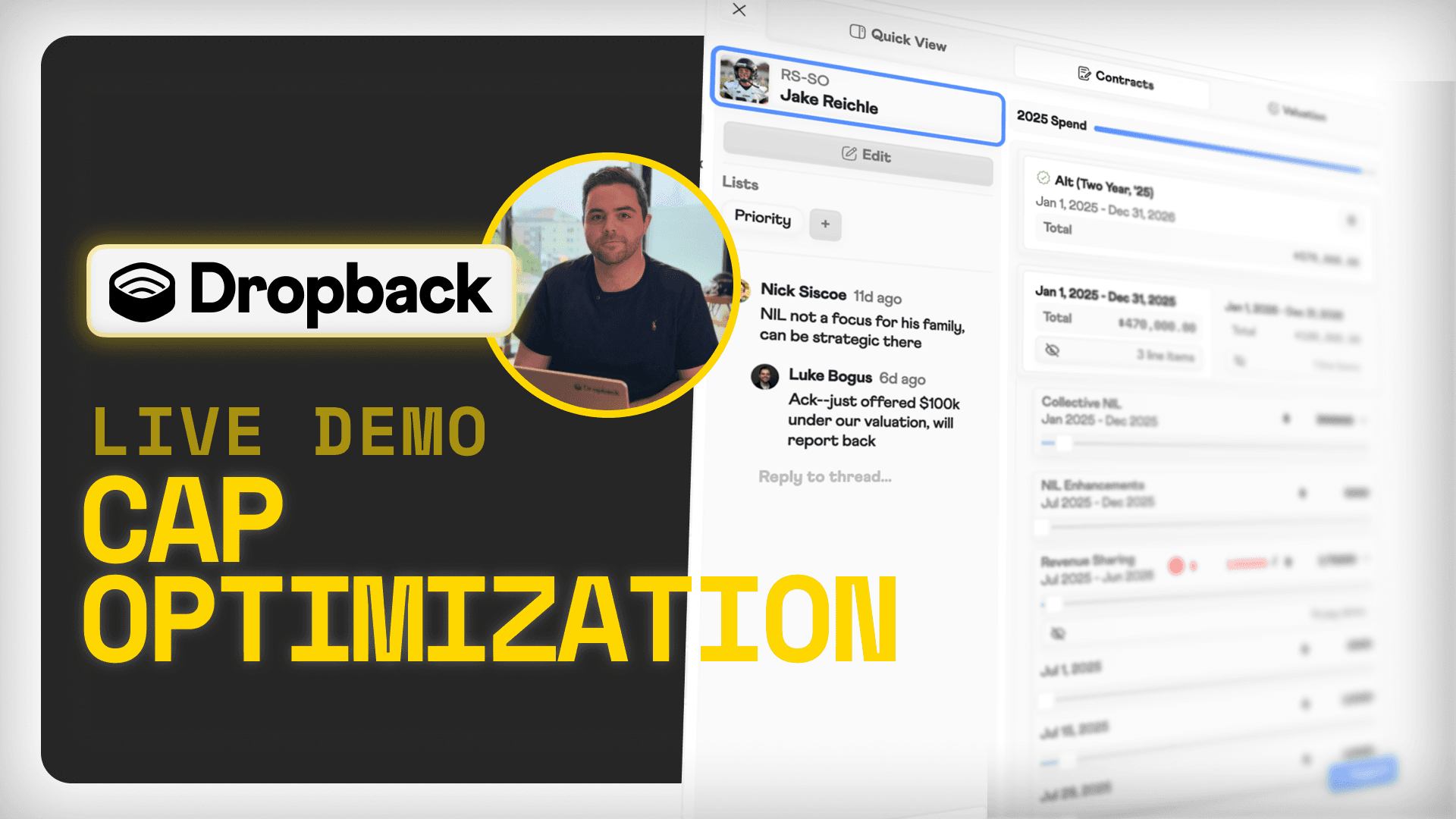
This Engine will soon run underneath the Dropback app you know — the cap modeling, the roster screens, the analytics your staff uses every day.
What's new is that we're opening the Engine itself. Today we're announcing three things.
1) A deployable database
No sports data company in the last two decades has been incentivized to launch a solution like this. They want to push their own data, first and foremost. They've never built a standardized solution for all data, including from external sources.
The Data Engine is different. It's the database infrastructure you need to build your dream Front Office workflows: New dashboards, charts, reports, and even AI agents.
Before Dropback, you could not stand up a decade of identity resolution, historical correctness, and live integration in an afternoon — or even two years — and then keep it running through every transfer window and every realignment.
Now, analysts and developers can stand up a custom interface in an afternoon.
2) Built for frame-level scale, proprietary by design
Because identity, history, and truth are handled cleanly underneath, you don't have to think about scale or latency on the Engine. The results are remarkable:
- < 500ms queries spanning any number of players, teams, games, plays, frames, and seasons
- Any change in information reaches every live view that depends on it in < 2 seconds
- < 50 milliseconds reactive roster page loads
- The same foundation that holds hundreds of thousands of players reaches down to play-by-play in the hundreds of millions of rows, and is architected to absorb tracking data at sixty frames per second — into the trillions of points — without re-platforming
The Engine's analytical core runs on ClickHouse, the open-source columnar database that powers real-time data substrates at Netflix, Uber, and Cloudflare — companies that move more rows per second than any sports league will produce in a decade. It's purpose-built for the workload sports data demands: hundreds of millions of rows scanned, joined, and aggregated in milliseconds, with headroom to reach frame-level tracking without re-platforming. We didn't pick it because it's trendy. We picked it because nothing else in the world handles trillion-row analytical workloads at sub-second latency the way it does.
A program's edge is in the questions it asks and the conclusions it draws. Those don't leave the Engine. Your data is encrypted in transit and at rest, never used to train external models, and held in cloud infrastructure with a track record measured in decades. Tenants are isolated at the database layer, not by application-level checks.
3) A toolkit to access the Engine
To make all of this addressable from outside the Dropback app, we're shipping a developer surface alongside the Engine itself:
- API — programmatic, identity-resolved, time-aware access for analysts and data teams. Pull a player's full history with one call. Reconstruct any roster as of any week.
- MCP server — the Engine becomes a first-class tool for any LLM agent. A language model can tell you about the internet. It cannot tell you about your program, because it has never seen your data. Our MCP server is the bridge: ground truth first, intelligence on top. The assistants you build on it can finally reason over what is actually true about your players, because something underneath them did the brutal work of making the data agree.
- Examples — custom dashboards stood up in an afternoon, bespoke analytical pipelines that share canonical identity with the rest of your stack, vibe-coded internal tools that don't break the moment a vendor changes a schema.
The programs that win this era won't be the ones with the most data. Everyone already has too much.
They'll be the ones whose data tells the truth about who, about when, and about what their own people believe.
The winners will build on top of that truth faster than anyone else can.